
MonkeyOCR 是一款基于轻量级文档解析模型的 OCR 工具,参数量仅为 3B,却在性能上超越了 Gemini 2.5 Pro 等闭源模型。它不仅能高精度识别文字、公式和表格,还能完整保留原始文档的结构与布局关系。
Colab 安装介绍
接下来介绍使用 Colab 的 T4 GPU 来测试使用,看看效果如何。
拉取项目
首先需要拉取官方的项目代码到本地
| |
然后我们需要手动输入命令去切换到项目目录来
| |
安装 CUDA 支持
首先我们要先看一下当前的 CUDA 版本
| |
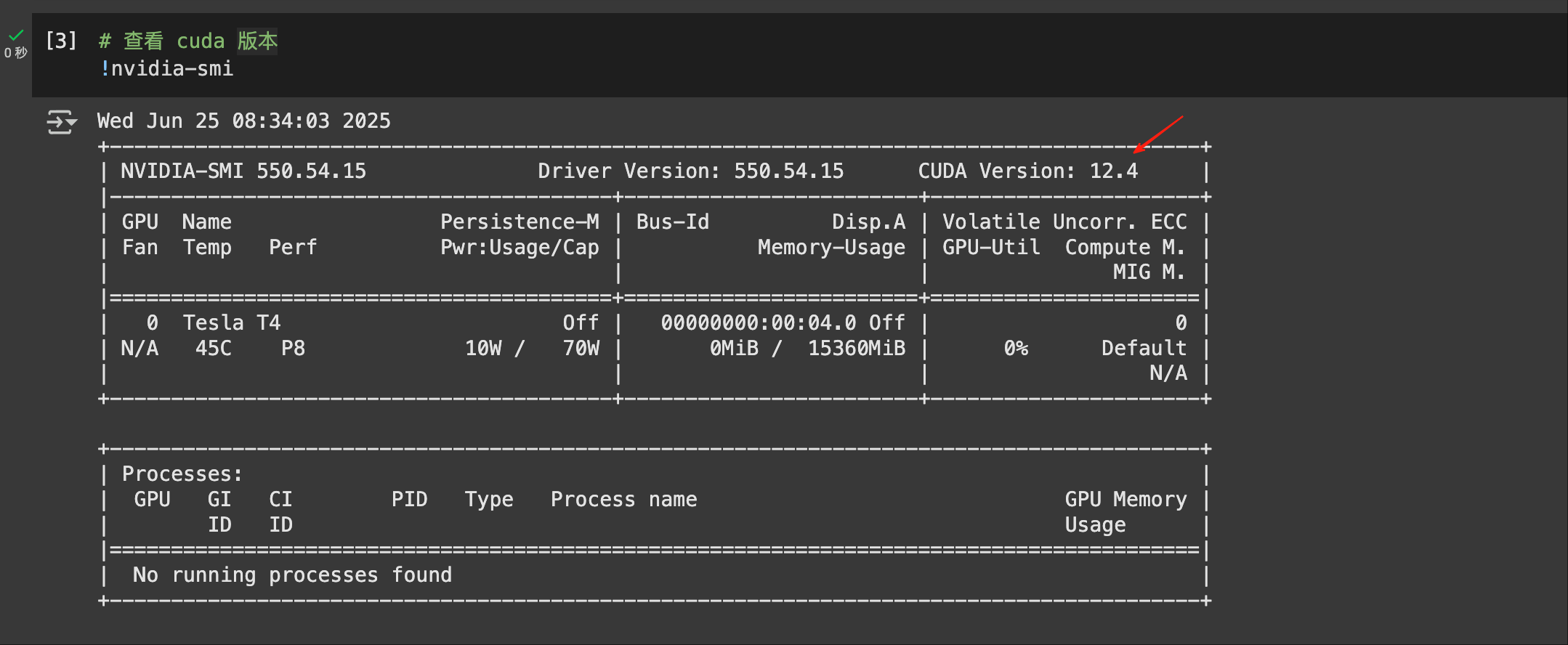
从上图可以看到是 12.4 的版本,所以我们就安装对应的版本依赖包
| |
安装 LMDeploy
LMDeploy 是一个高效且友好的 LLM 模型部署工具箱,功能涵盖了量化、推理和服务。
| |
安装项目依赖
| |
下载模型
如果使用 Huggingface 下载模型,可以执行以下命令,不过一般 Colab 已经自带
| |
或者可以使用 modelscope
| |
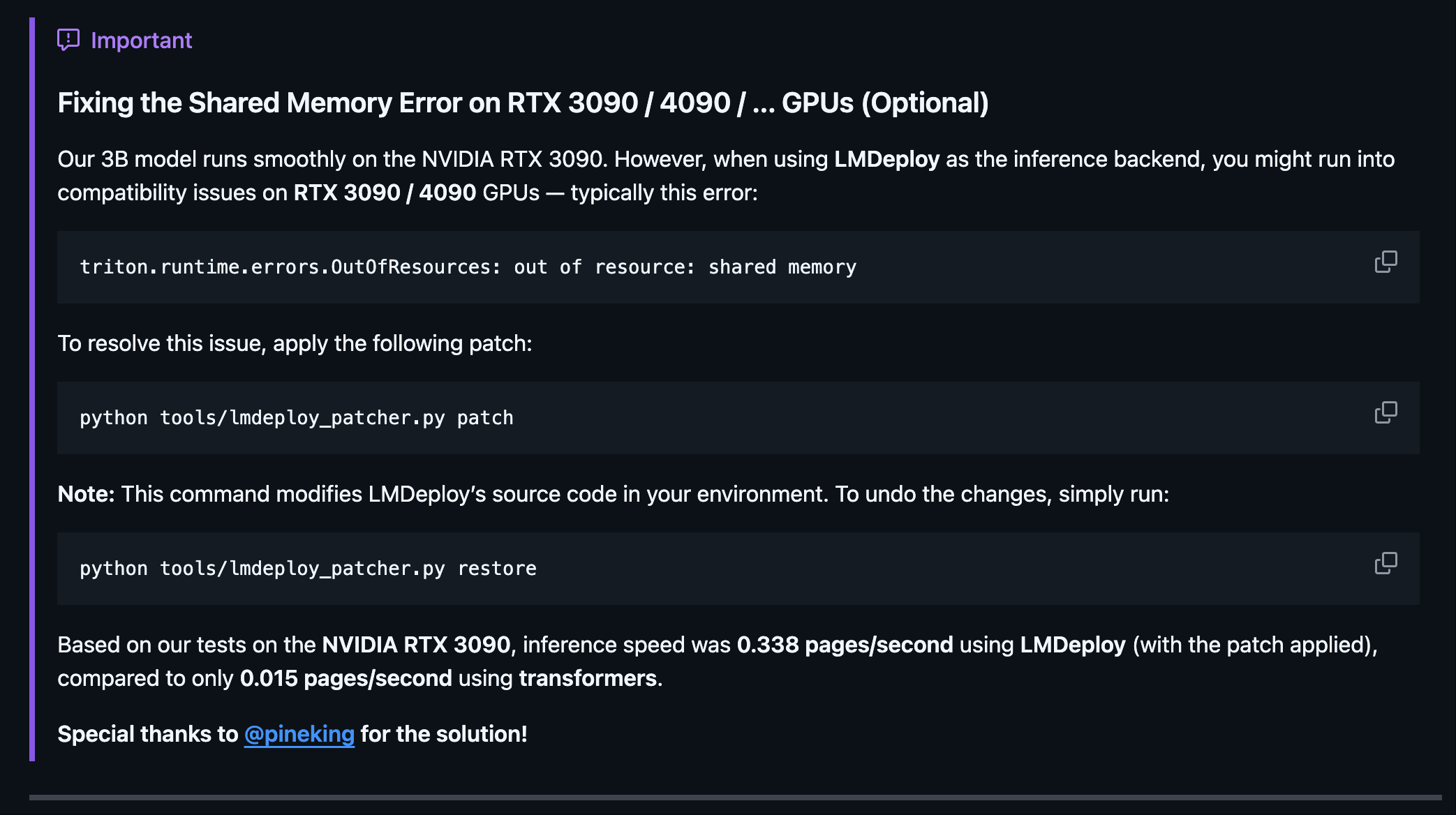
修复 T4 显卡问题:Shared Memory Error 问题 (可选)
如果使用的 T4 显卡的话,在执行任务的时候,就会提示 Shared Memory Error 的错误。主要是因为 Flash Attention 使用的共享内存超过了 GPU 的硬件限制, T4 显卡在 Compute Capability 7.5 (Turing) 上,每个线程块(block)的最大共享内存为:
48 KB = 49152 Bytes
而程序申请了 65538 字节 ,远远超过了硬件限制。
| |
官方文档上也有对于不同的显卡做了说明。
https://github.com/Yuliang-Liu/MonkeyOCR/blob/main/docs/install_cuda.md#install-with-cuda-support
效果测试
测试1
我们使用一张带图片的 pdf 文档来试试
执行以下命令进行解析
| |
如果没有报错的话,就可以看到如下图的内容
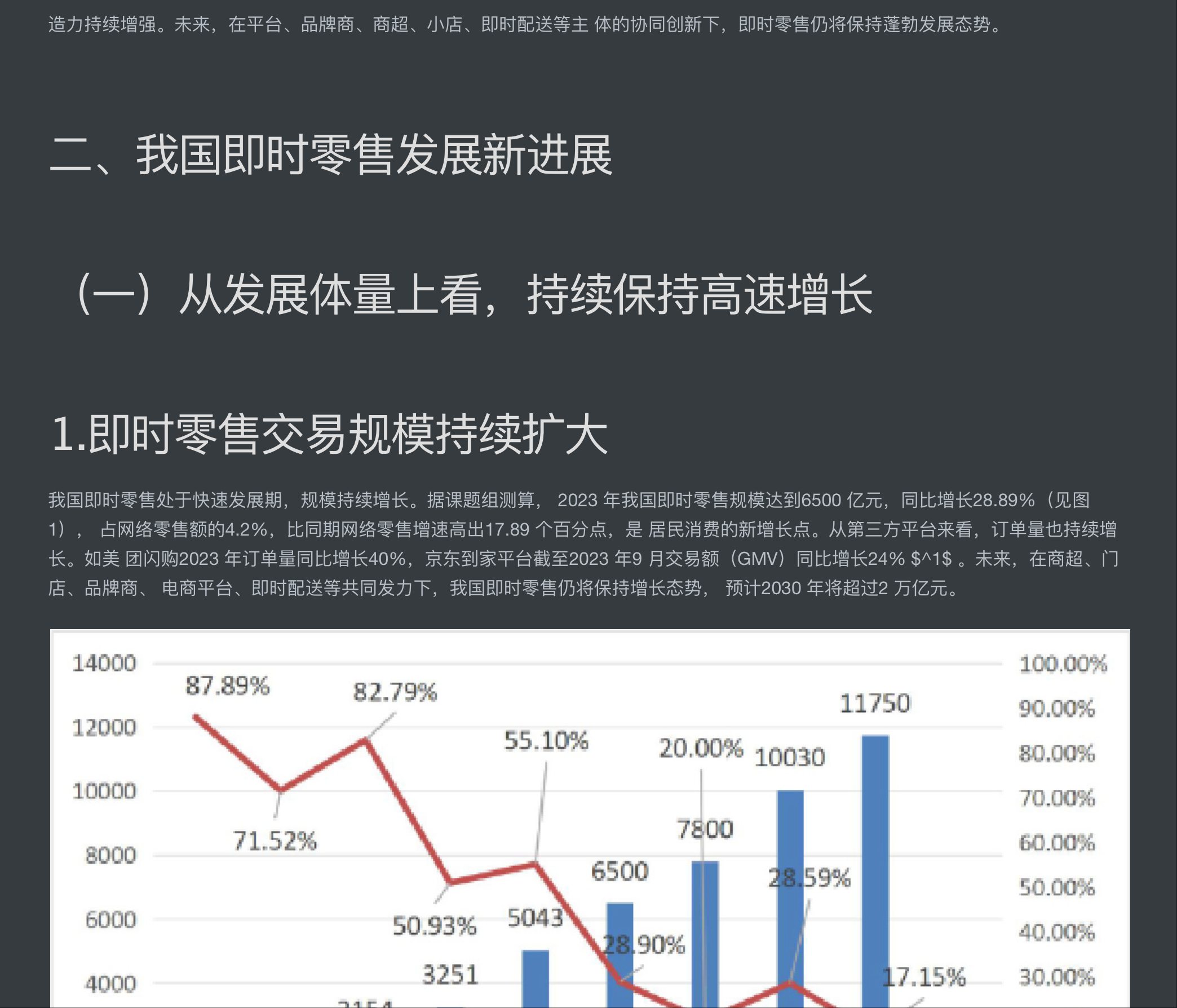
我们将它打包下载到本地看一下,排版、标题等基本跟 pdf 一致
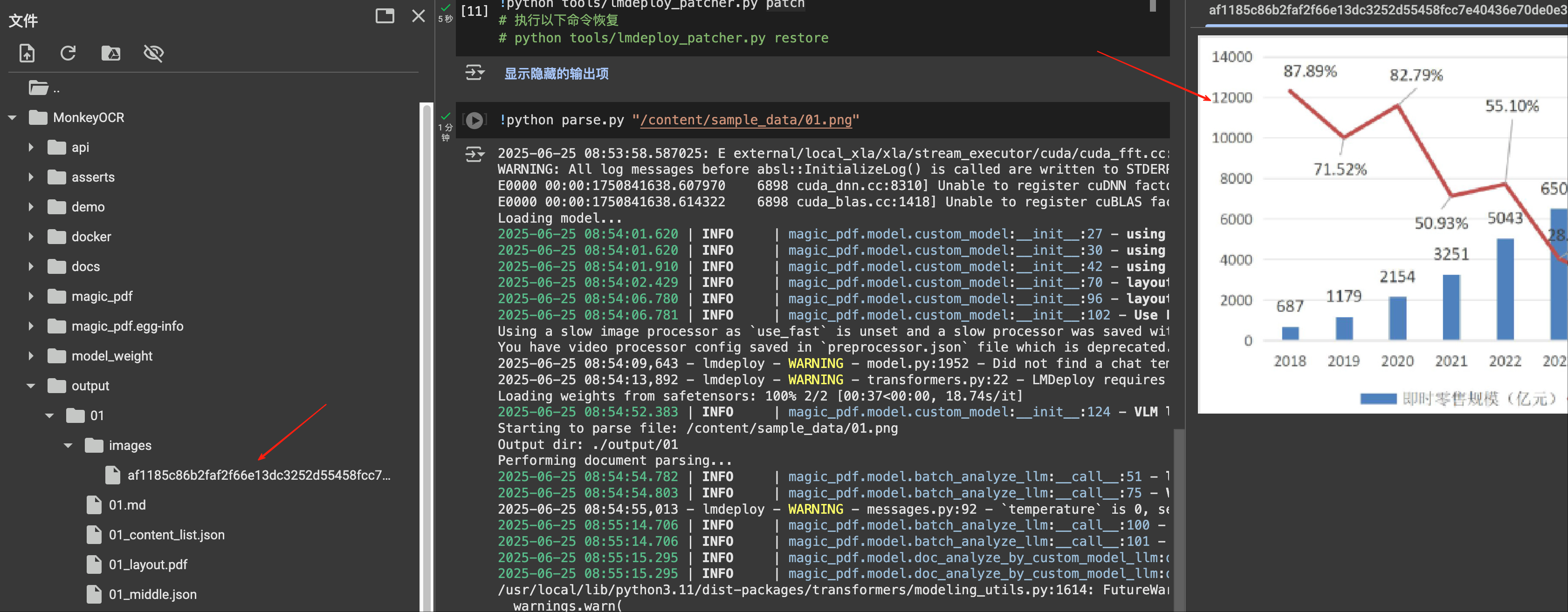
而且图片也能够单独识别出来,放在统一的文件夹内
测试2
我们使用一张带表格的 pdf 文档来试试

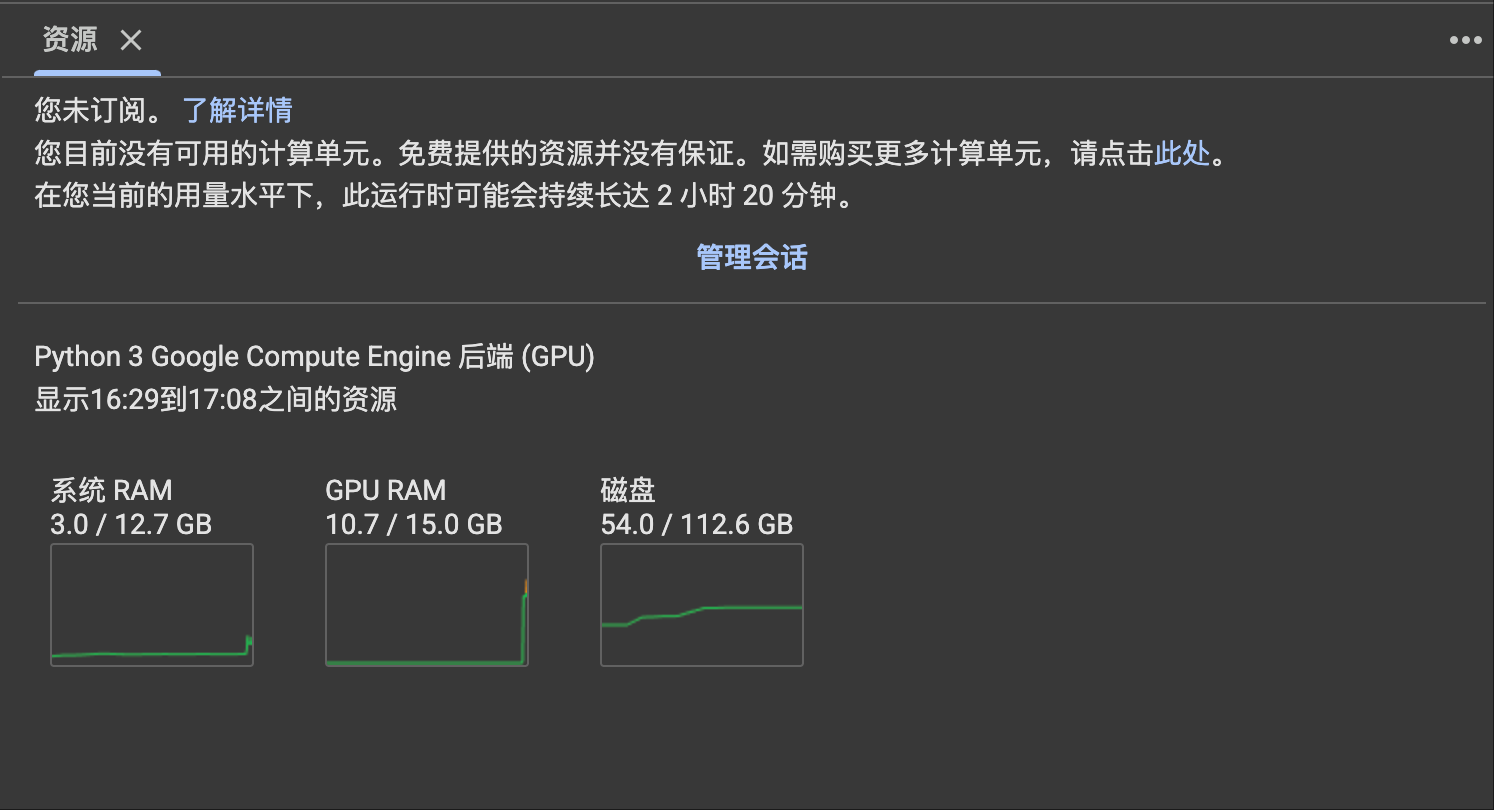
从资源面板看到,在运行的时候,大概使用了 10G 的显卡显存
这次用了 15 秒左右
本地打开看一下效果,表格能很好的识别出来了

总结
从两次测试来看,都能够很好的识别到 pdf 中的内容,不管是图片还是表格,这种在以前 ocr 工具中效果不太好的情况,在 MonkeyOCR 工具中,有了很好的改善。
然后模型大小只有 3B 参数,但是对于显卡的要求还是比较高的,一般入门级别的显卡可能就有点吃力了。
目前这款工具能够支持 中文 和 英文,后续可能还会支持更多的语种。