模型已经更新到
Qwen-Image-Edit-2509
新模型下载地址
| |
其他的节点模型不变,在工作流中的模型节点切换到新的 2509 模型即可
注意需要先将 ComfyUI 版本升级到 0.3.51 以上版本
模型下载
可使用 hf-mirror.com 进行国内加速下载,例如 https://hf-mirror.com/Comfy-Org/Qwen-Image-Edit_ComfyUI/resolve/main/split_files/diffusion_models/qwen_image_edit_fp8_e4m3fn.safetensors
qwen_image_edit_fp8_e4m3fn.safetensors
下载放置 ComfyUI/models/diffusion_models 目录中
| |
Qwen-Image-Lightning-4steps-V1.0.safetensors
下载放置 ComfyUI/models/loras 目录中
| |
qwen_2.5_vl_7b_fp8_scaled.safetensors
下载放置 ComfyUI/models/text_encoders 目录中
| |
qwen_image_vae.safetensors
下载放置 ComfyUI/models/vae 目录中
| |
模型目录大概如下所示:
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── qwen_image_edit_fp8_e4m3fn.safetensors
│ ├── 📂 loras/
│ │ └── Qwen-Image-Lightning-4steps-V1.0.safetensors
│ ├── 📂 vae/
│ │ └── qwen_image_vae.safetensors
│ └── 📂 text_encoders/
│ └── qwen_2.5_vl_7b_fp8_scaled.safetensors
工作流
下载工作流并导入到 ComfyUI
| |
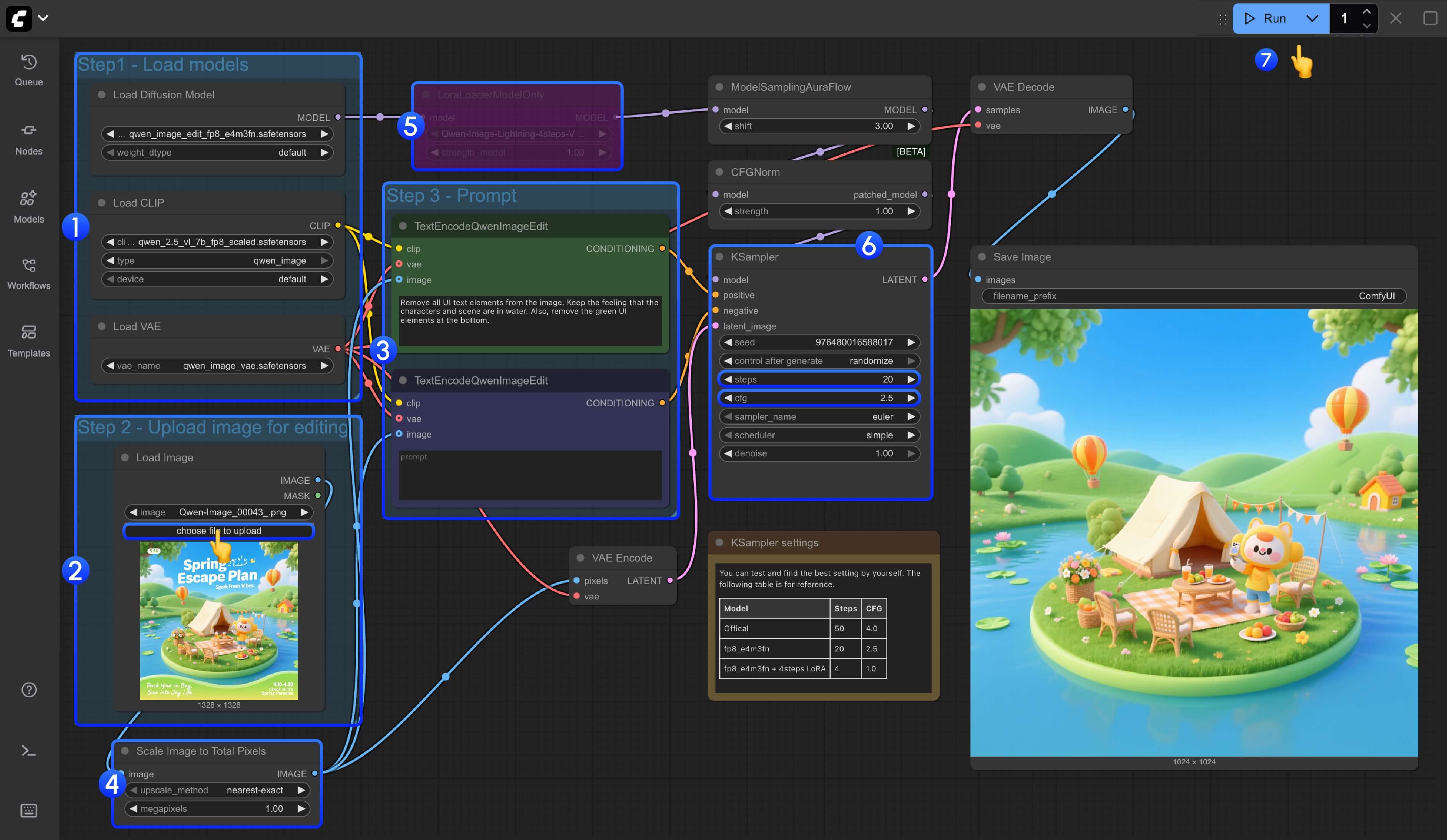
步骤
1. 模型加载
- 确保 Load Diffusion Model 节点加载文件:
qwen_image_edit_fp8_e4m3fn.safetensors - 确保 Load CLIP 节点加载文件:
qwen_2.5_vl_7b_fp8_scaled.safetensors - 确保 Load VAE 节点加载文件:
qwen_image_vae.safetensors
2. 图像加载
- 确保 Load Image 节点上传了需要编辑的图像。
3. 提示词设置
- 在 CLIP Text Encoder 节点中设置提示词(prompt)。
4. 图像缩放设置
- Scale Image to Total Pixels 节点会将输入图像缩放到总像素数为 100 万(例如 1024×976),
主要用于避免因输入图像过大(如 2048×2048)导致输出图像质量下降。 - 如果熟悉输入图像尺寸,可使用快捷键
Ctrl+B跳过此节点。
5. 启用 4 步光照 LoRA(可选)
- 若想使用 4 步光照 LoRA 加速图像生成,可选中 LoraLoaderModelOnly 节点,并按
Ctrl+B启用。
6. Ksampler 参数调整
- 对于 Ksampler 节点的
steps和cfg设置,已在节点下方添加了注释说明,可在此测试并找到最优参数组合。
7. 运行工作流
- 点击 Queue 按钮,或使用快捷键
Ctrl/Cmd + Enter来运行工作流。
功能介绍
列举一些官方的使用示例
视觉转换
可以创作一些三视图

AI 新增
就是可以在原图的基础上添加一些新的物体

AI 消除
哪怕是像头发丝这么细的物体也可以消除(碟子上的头发丝)

海报编辑
可以对海报上的文字进行编辑,还可以换掉里面的主体人物等
