WeKnora 基于大模型的新一代文档理解与检索框架
WeKnora 是由腾讯开源的企业级文档智能理解框架,基于大语言模型(LLM)构建,专注于 异构文档的深度解析 与 上下文感知的语义检索。 其核心价值在于通过多模态融合与知识图谱增强技术,实现复杂文档的精准理解,提供类人级的问答体验。 项目采用 RAG(Retrieval-Augmented Generation)架构,已在微信对话开放平台实现日均亿级调用。
安装
主要介绍 docker 方式进行安装
克隆仓库
| |
配置
| |
主要需要注意一下里面的一些端口会不会跟目前服务器的在用端口冲突
| |
还有这边默认是使用 Ollama 服务的,如果有需要的话,可以配置一下。但是也可以不配置,所以 OpenAI 兼容接口也是可以的
| |
启动
使用 docker compose 方式启动,需要稍等片刻等拉取镜像,国内可以先配置国内镜像源加速
| |
使用
如果没改 FRONTEND_PORT 配置的话,就在浏览器打开服务器 IP 即可访问了,如下图所示。因为我这边没配置 Ollama 服务,所以这边就提示默认的链接失败了。
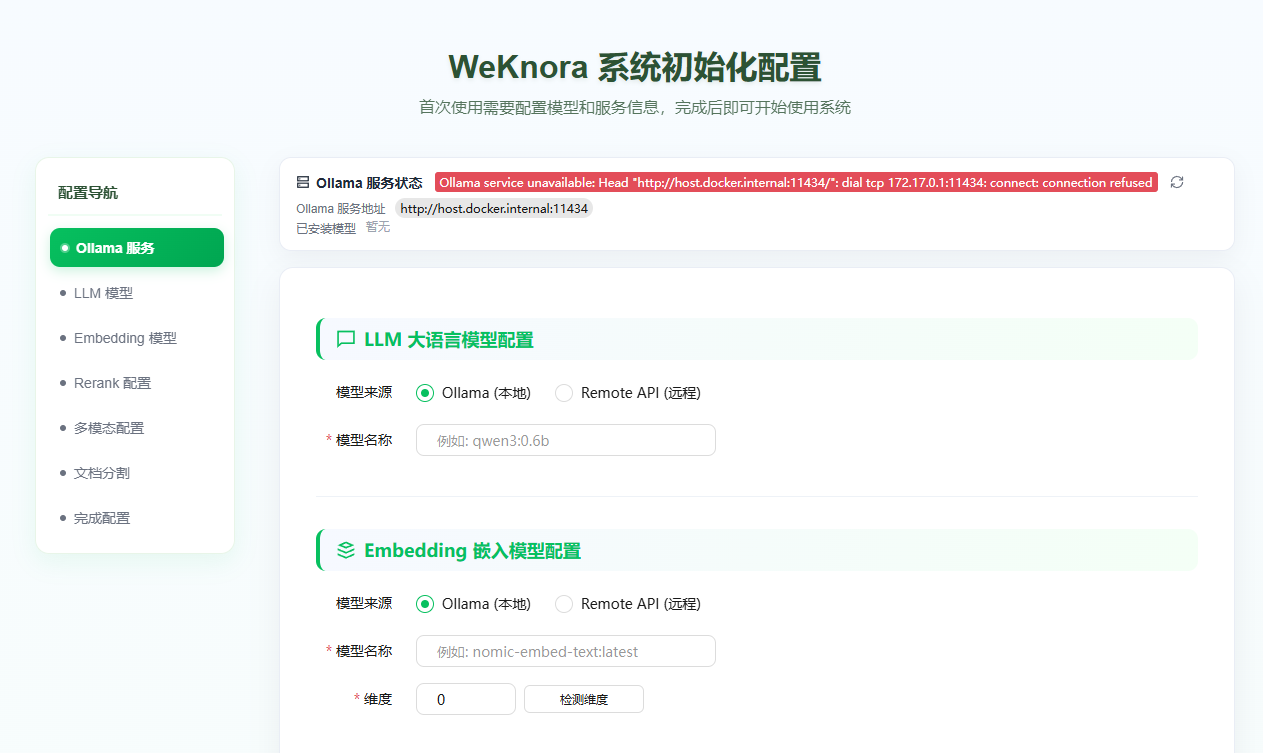
但是这里可以配置一些 OpenAI 接口兼容的提供商的 API 也是可以的,例如使用 硅基流动 平台的。但是出于数据安全考虑,还是建议使用私有部署的模型服务。
模型配置
以下方便演示我就选择使用 硅基流动,在 嵌入模型 方面,它提供了一些免费的模型,例如 BAAI/bge-m3
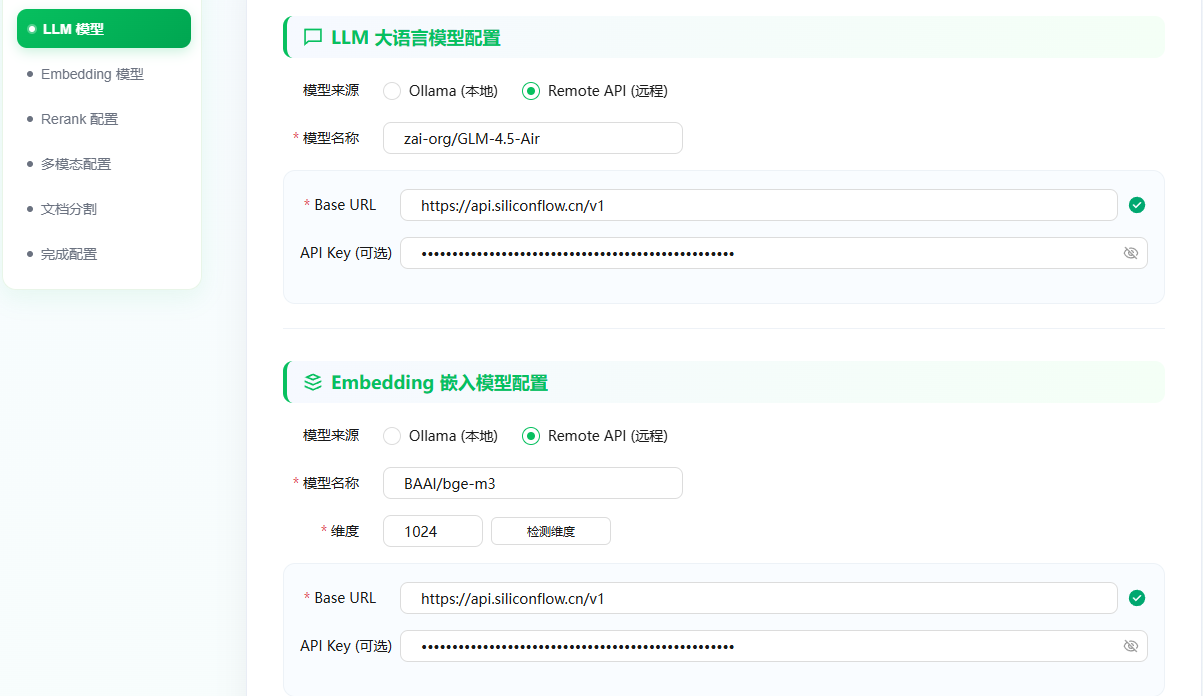
为了提高检索效果,我还配置了 重排模型,使用的是 BAAI/bge-reranker-v2-m3 ,目前在平台也是免费使用的
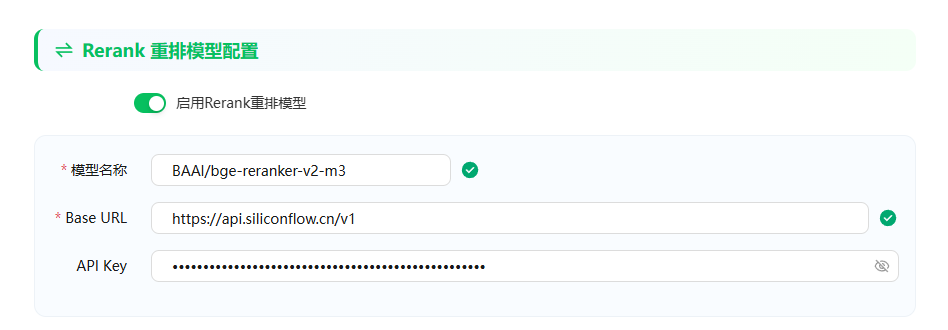
配置好后,就可以点击底下的完成按钮
知识库
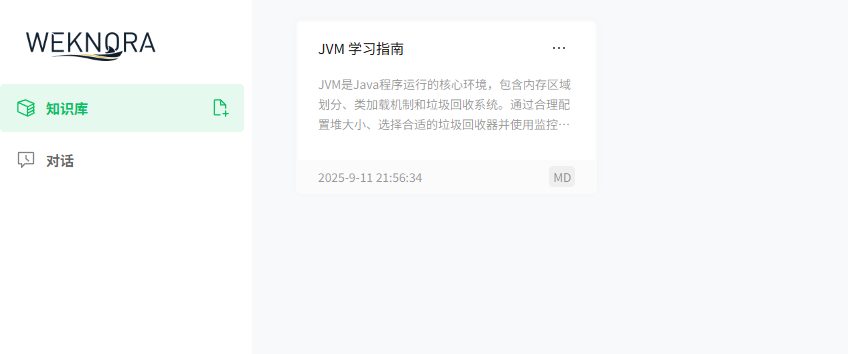
完成上面的配置后,就提示可以上传自己的知识库文档了

接下来尝试上传一份 markdown 格式的文档,内容为 JVM 学习指南 介绍的文章
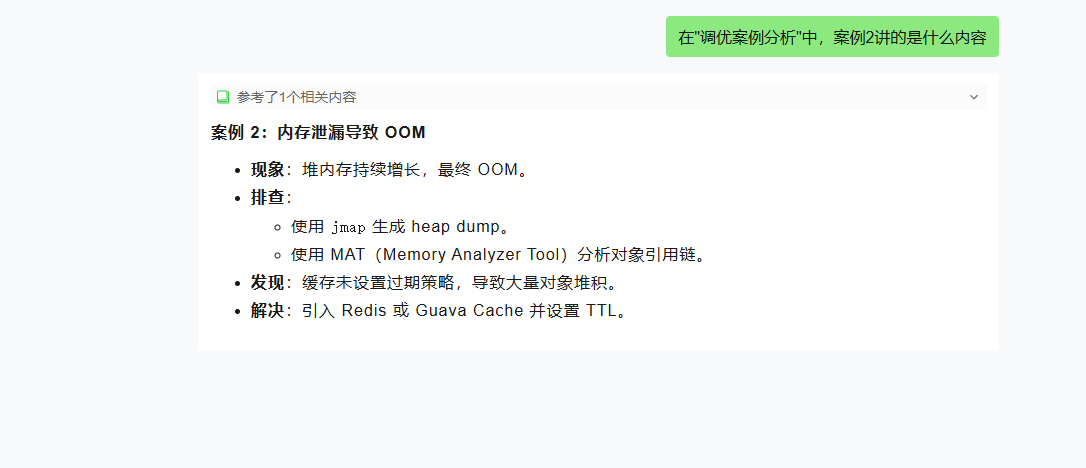
上传成功过后,我们就可以根据这个知识库进行聊天对话,例如问一下这里的案例2讲的什么内容

能准确定位到文档的相关部分,而且还能很完整的将内容回复出来,包括 markdown 格式
接下来试试 pdf 文档,内容为 Redis持久化策略 介绍的文档,里面会有一些配图
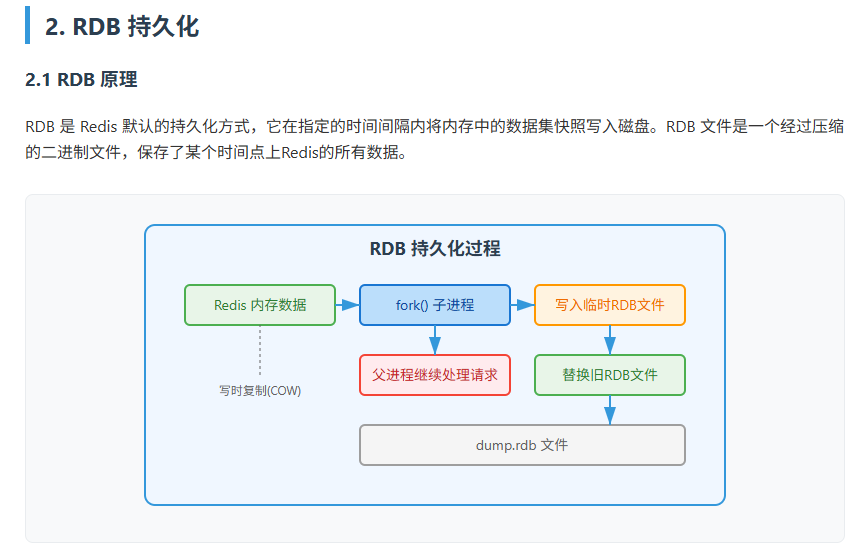
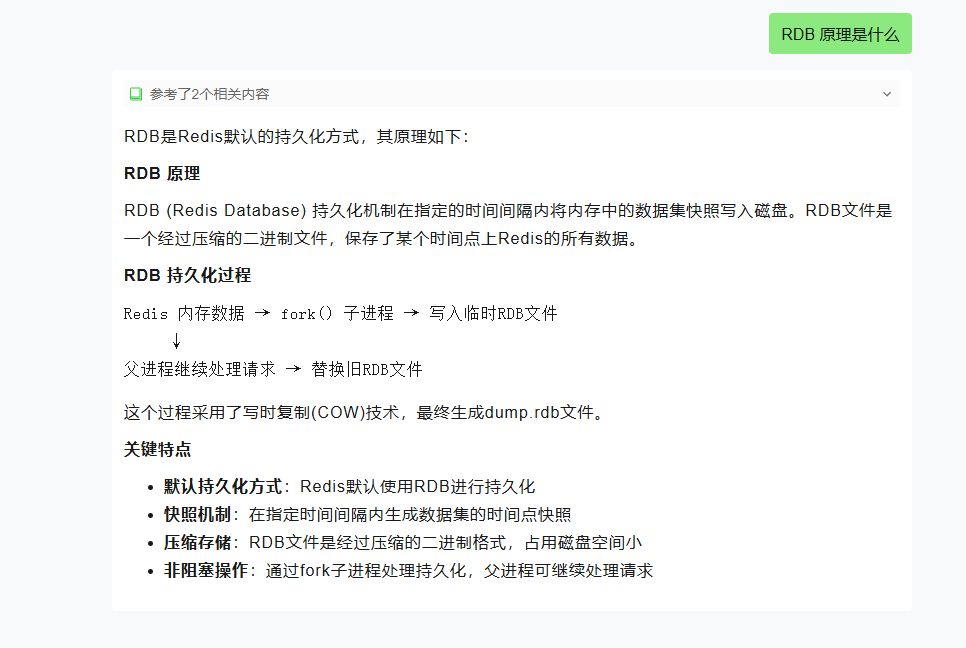
我们就直接问一下 RDB 原理,对应文档中的内容如下
可能文中的图原本是用 svg 代码写的,所以回复的内容也没有很好的进行渲染
API 调用
官方还提供 API 调用的文档介绍,即这套框架支持使用 RESTful API 来进行管理,而且还支持 租户管理 功能

但是我们先需要调用接口创建一个新的租户,然后就会返回对应的 api_key
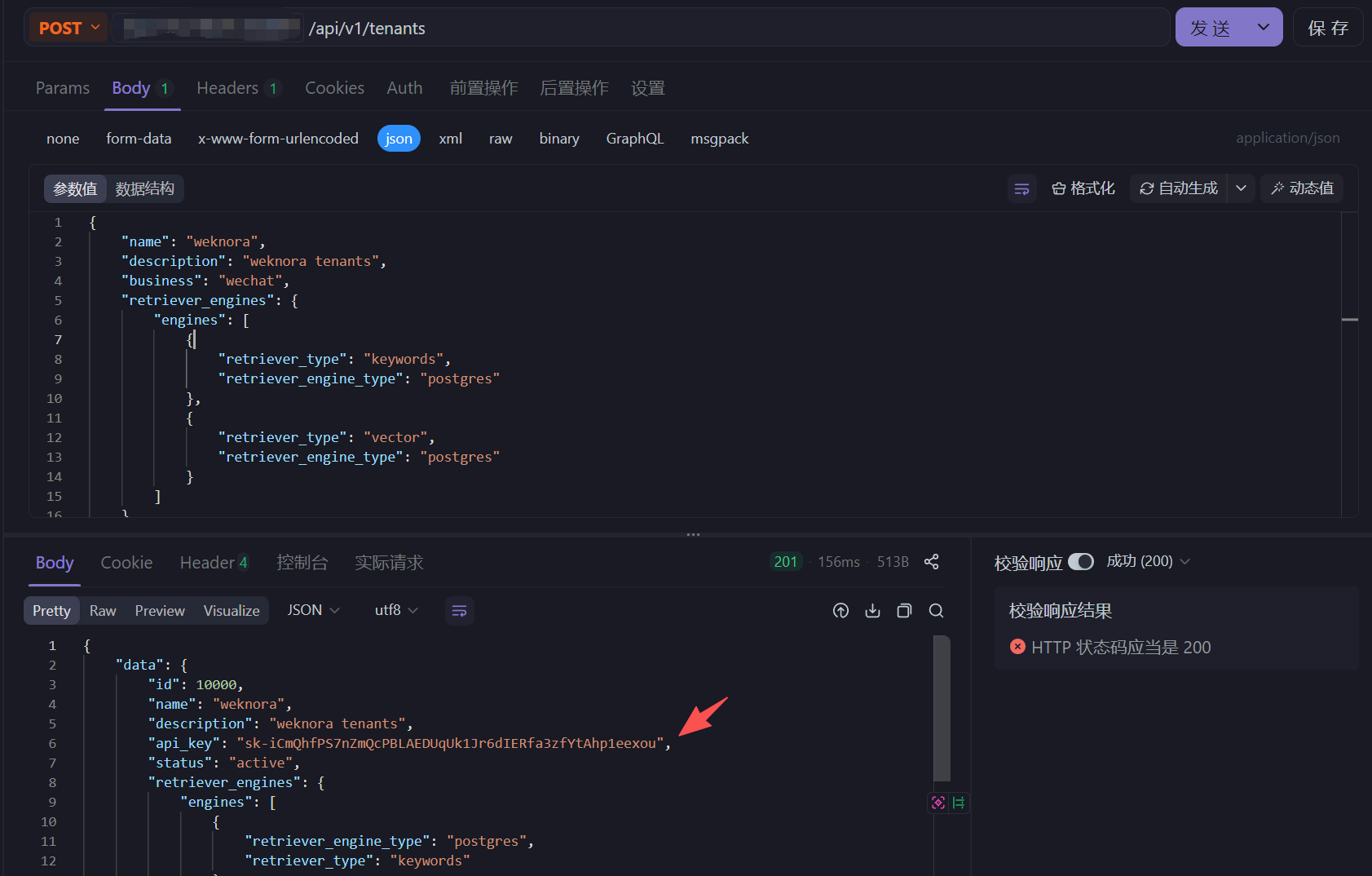
往后的所有调用的接口,都需要带上这个 api_key
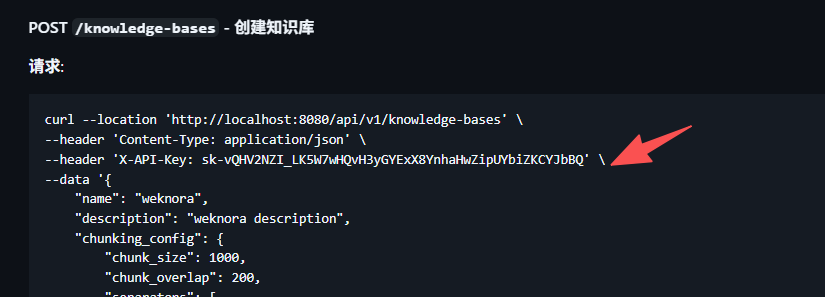
而且基于多租户的,像知识库、模型等那些都需要调用接口重新设置一次,还挺麻烦的。基于目前这个框架才刚起步,后台也做得很简陋,后续应该会添加更多人性化的功能。