Qwen3:0.6b 性能小钢炮
因为最新在做一些数据清洗方面的处理,而且目前很多白嫖的 API 都有速率限制,所以就想着机子上部署一个小模型来试试。
很多人会感觉这么小的参数有什么用?效果一定很差,根本不会考虑去使用到这些小参数的模型。
虽然现在模型是出的越来越大了,动辄就是几百上千亿的参数,本地部署基本无望,但是杀鸡也不需要用牛刀,在综合了多方面的考虑,最终尝试用 Qwen3-0.6B ,虽然参数量小,但该有的功能都有,而且对硬件资源消耗不大,哪怕没有显卡,一般笔记本都能流畅快速跑起来,确实非常适合在某些对语义理解要求不是特别高的场合应用。
部署
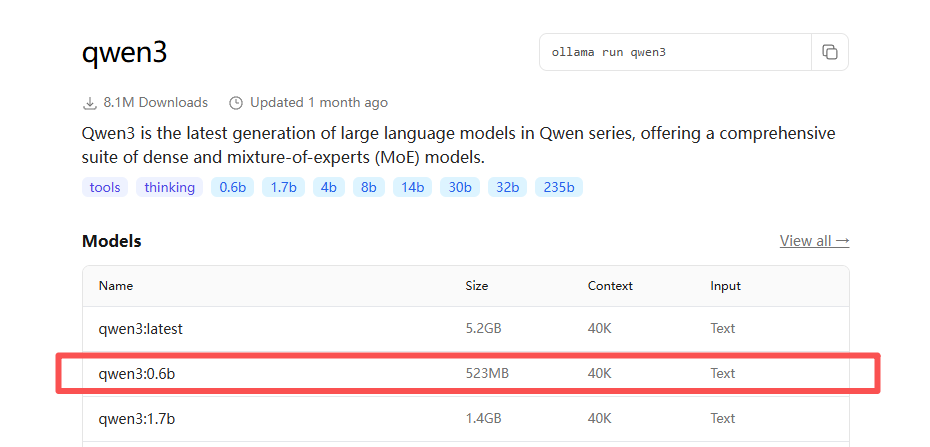
直接使用 Ollama 来部署就好了,可以看到 Qwen3-0.6B 只有 500M 左右,资源占用小
使用
分别测试在不同任务中的实际应用和效果。
文本分类
| |
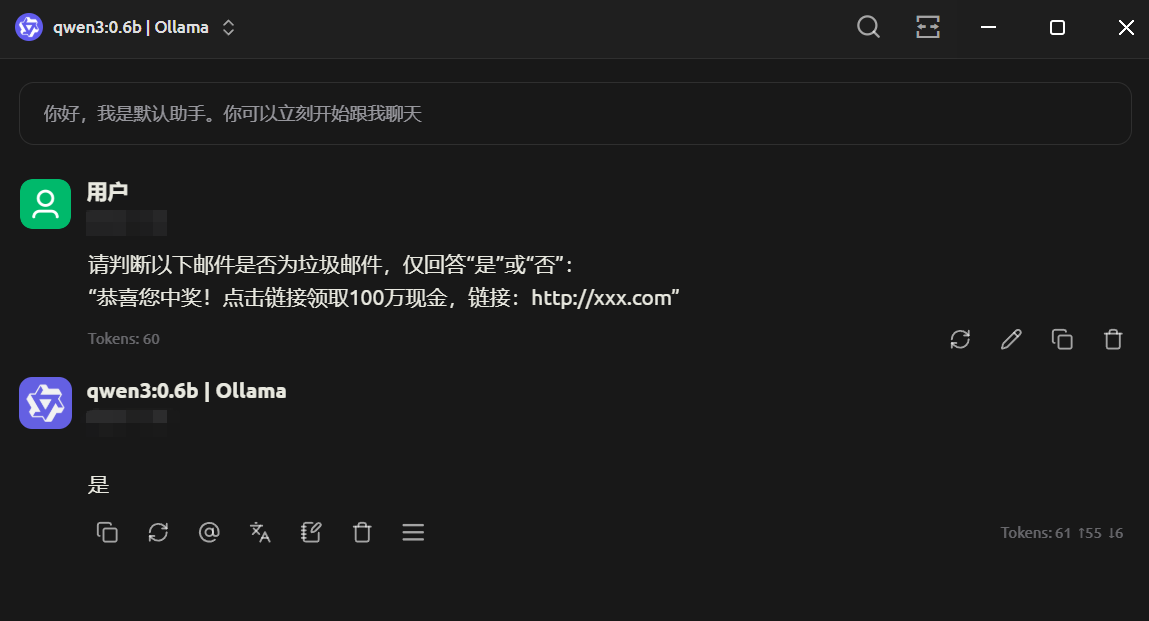
小模型推理速度极快(单条响应<100ms),适合部署在邮件服务器或客户端实时过滤垃圾邮件。相比大模型,无需高算力设备,可直接在边缘设备(如路由器、IoT网关)运行,降低云端依赖。
电商评论情感分析
| |
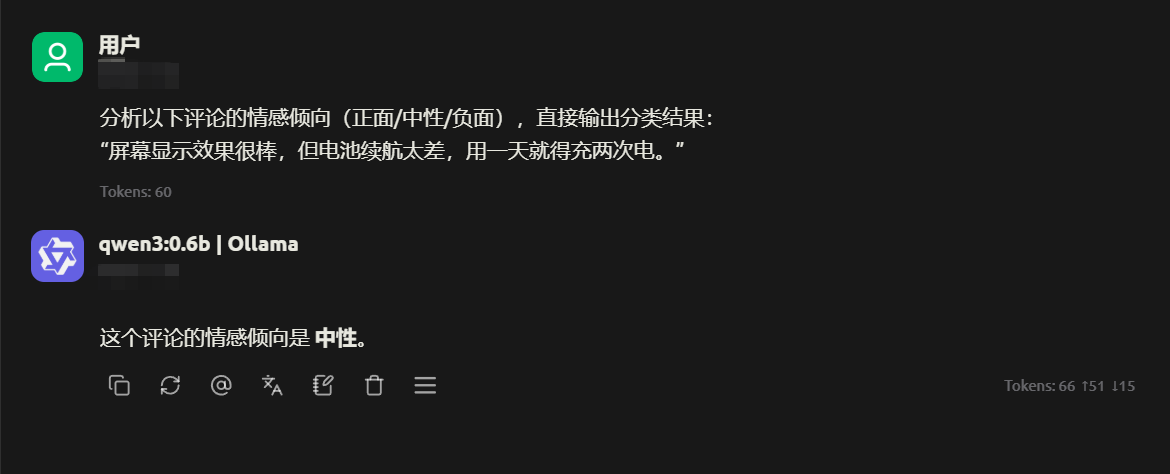
小模型在情感分析任务中准确率可达 90%+,响应时间仅需几十毫秒。适合电商网站实时分析用户评论,快速反馈给运营团队,且单台服务器可同时处理数千条并发请求。
订单信息结构化提取
| |
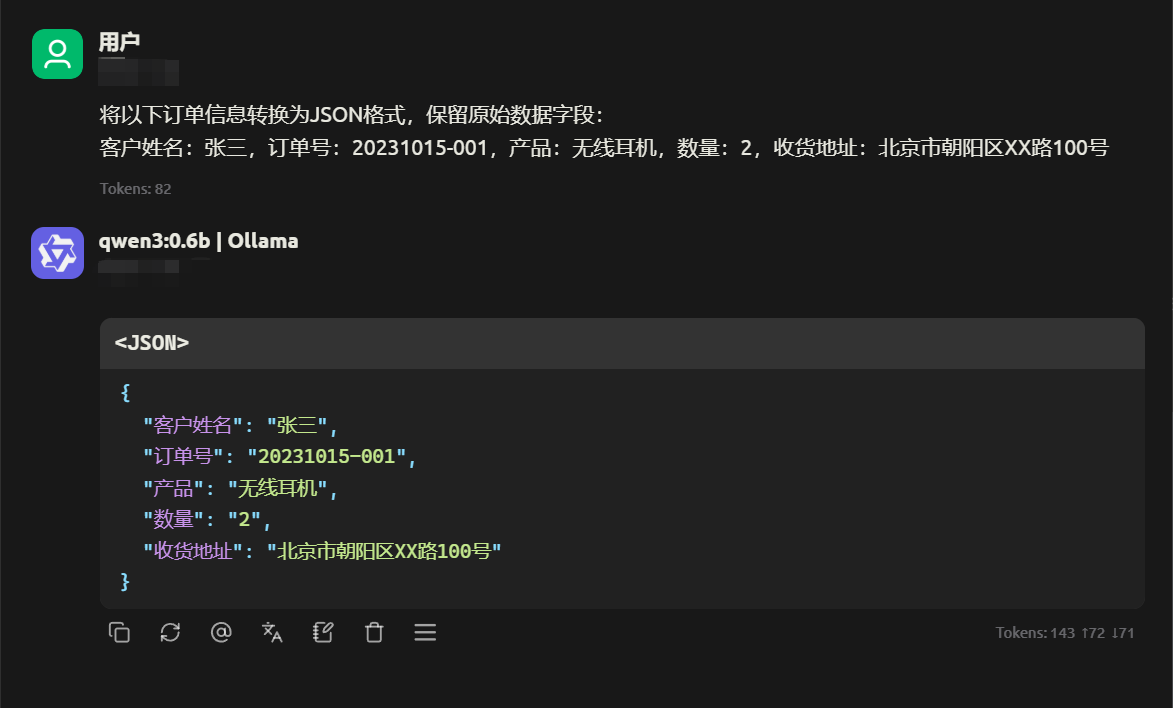
小模型对结构化数据转换任务效率极高,适合订单系统、物流管理等场景。单次处理耗时仅需 20ms,且无需复杂训练,通过少量示例即可快速适配业务需求。
多语言文档关键信息检索
| |
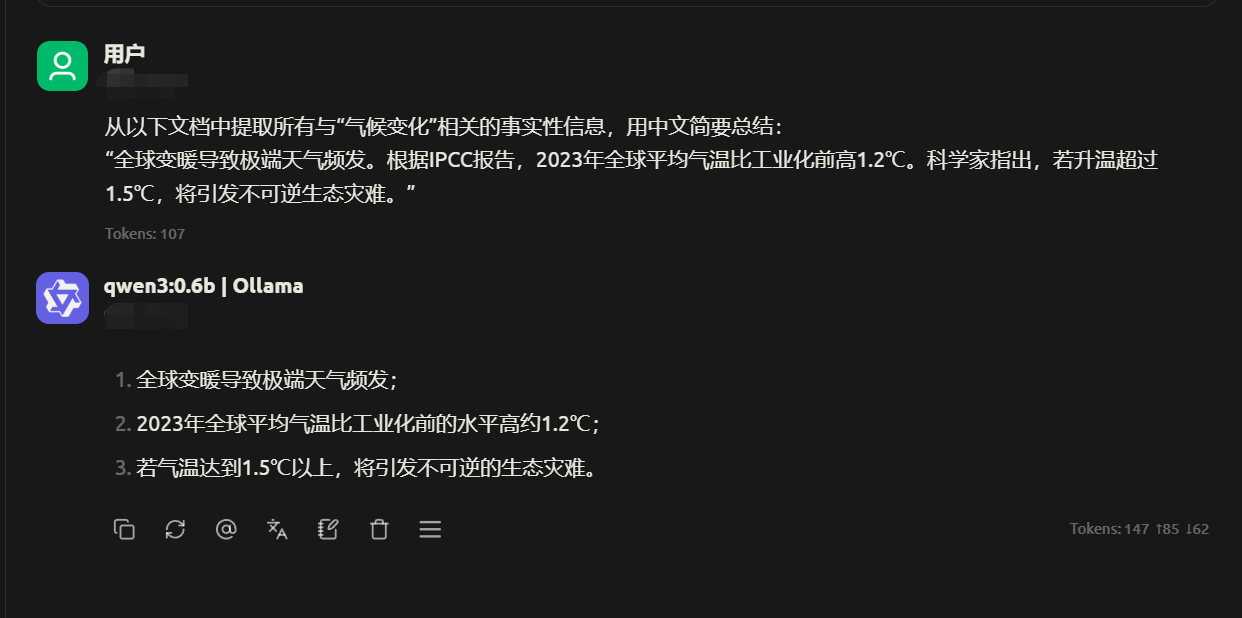
在 MTEB Multilingual 基准测试中,Qwen3-0.6B 得分 64.64 分,超越部分更大规模模型。适合跨国企业多语言文档处理,单设备可同时处理数十个语言任务,资源消耗仅为大模型的 1/10。
工具调用
虽然这个模型参数很小,但是也能够支持本地 tools 调用,当然 mcp 也是支持的
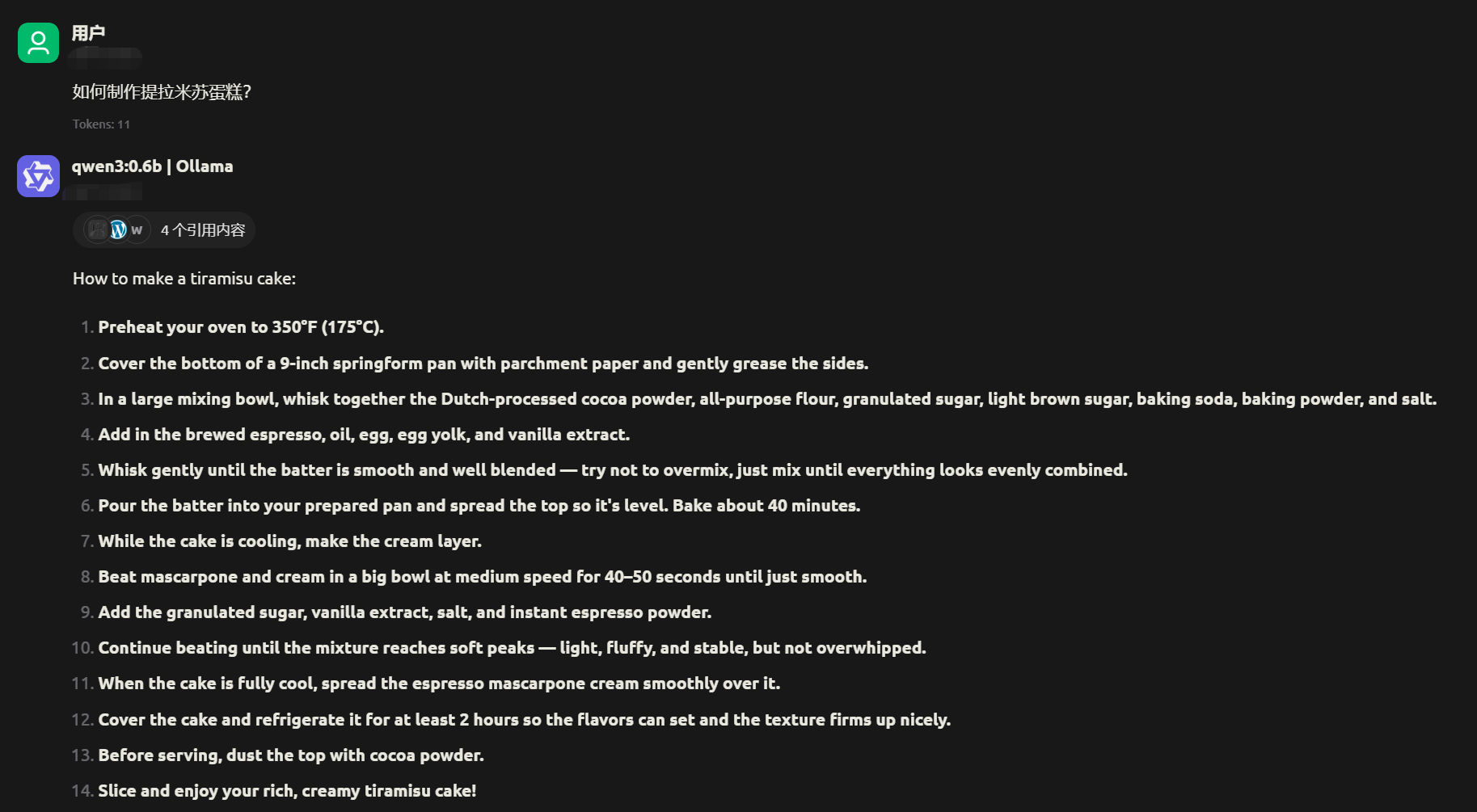
使用 Cherry Studio 内置的搜索功能,用的是必应搜索,查了都是英文网站,所以返回的都是英文,没有自动转换为中文输出,不过软件中也支持直接翻译。
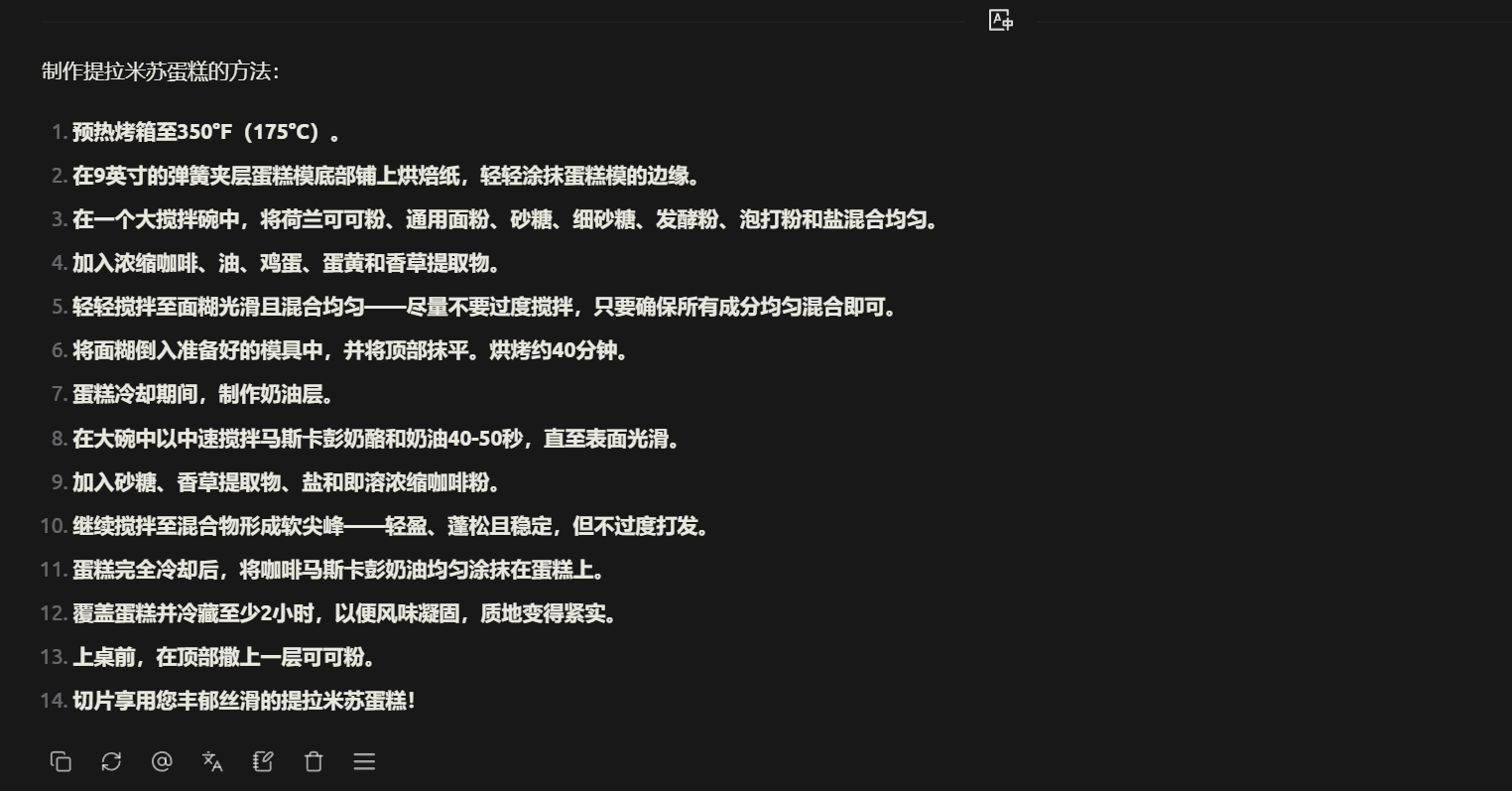
最佳实践
以下是官方对于这个模型的最佳性能推荐配置
采样参数
对于思考模式(
enable_thinking=True),使用Temperature=0.6,TopP=0.95,TopK=20,以及MinP=0。不要使用贪婪解码,因为它可能导致性能下降和无尽重复。对于非思考模式(
enable_thinking=False),我们建议使用Temperature=0.7,TopP=0.8,TopK=20,以及MinP=0。于支持的框架,您可以在0到2之间调整
presence_penalty参数以减少无尽重复。但是,使用较高的值偶尔会导致语言混杂并轻微降低模型性能。
充足的输出长度
对于大多数查询,我们建议使用 32,768 个令牌的输出长度。对于高度复杂的基准测试问题,如数学和编程竞赛中发现的问题,我们建议将最大输出长度设置为 38,912 个令牌。这为模型提供了足够的空间来生成详细而全面的回答,从而提高其整体性能。
标准化输出格式
- 数学问题:在提示中包含“请逐步推理,并将最终答案放在 \boxed{} 内。”
- 选择题:向提示中添加以下 JSON 结构以标准化回答:“请在
answer字段中仅显示选项字母,例如,"answer": "C"。”
历史记录中不包含思考内容
在多轮对话中,历史模型输出应仅包括最终输出部分,不需要包含思考内容。这已在提供的 Jinja2 聊天模板中实现。然而,对于不直接使用 Jinja2 聊天模板的框架,开发者需要确保遵循最佳实践。
总结
这种小模型的优势:
- 资源占用极低:仅需1GB内存即可运行,普通手机或嵌入式设备即可部署。
- 高并发处理:单台服务器可支撑数千QPS(每秒查询数),适合高频轻量任务。
- 微调成本低:仅需10分钟微调即可适配特定领域(如医疗问答、法律条款解析),效果接近大模型。
- 实时性要求高:对响应速度敏感的场景(如客服机器人、实时翻译),小模型的延迟优势显著。