B站开源 IndexTTS2 部署和使用
IndexTTS2 相对于上一个版本有了显著的提升,官方上写的是情感表达和时长控制的自回归零样本文本转语音的突破。
此外,IndexTTS2 实现了情感表达与说话者身份的分离,从而能够独立控制音色和情感。在零样本设置下,该模型可以准确地重建目标音色(来自音色提示),同时完美地再现指定的情感基调(来自风格提示)
克隆仓库
| |
关于 LFS
目前官方提供的 LFS 额度不够,所以不能够正常下载 demo 中的文件,只影响到 demo 的运行,如果有需要可以单独下载
https://drive.google.com/file/d/1o_dCMzwjaA2azbGOxAE7-4E7NbJkgdgO/view
安装依赖
使用 uv 包管理器进行安装
| |
安装 WebUI 支持
| |
可选功能:
--all-extras:安装全部可选功能。可去除自定义。--extra webui:安装WebUI支持(推荐)。--extra deepspeed:安装 DeepSpeed 加速。
如果使用 deepspeed 可能会提示错误:
| |
可以在虚拟环境中,先安装构建依赖:
| |
然后再单独安装 deepspeed
| |
如遇 CUDA 相关报错,请确保已安装 NVIDIA CUDA Toolkit 12.8及以上。
下载模型
HuggingFace 下载:
| |
ModelScope 下载:
| |
项目首次运行还会自动下载部分小模型。如网络访问 HuggingFace 较慢,建议提前设置:
1export HF_ENDPOINT="https://hf-mirror.com"
PyTorch GPU 加速检测
可运行脚本检测机器是否有 GPU,以及是否安装了 GPU 版本的 PyTorch。(如 PyTorch 版本不对,可能使用 CPU 启动,推理会非常慢)
| |
输出 PyTorch: NVIDIA CUDA / AMD ROCm is available! 代码可启用 GPU
| |
启动项目
| |
浏览器访问 http://127.0.0.1:7860 查看演示
效果
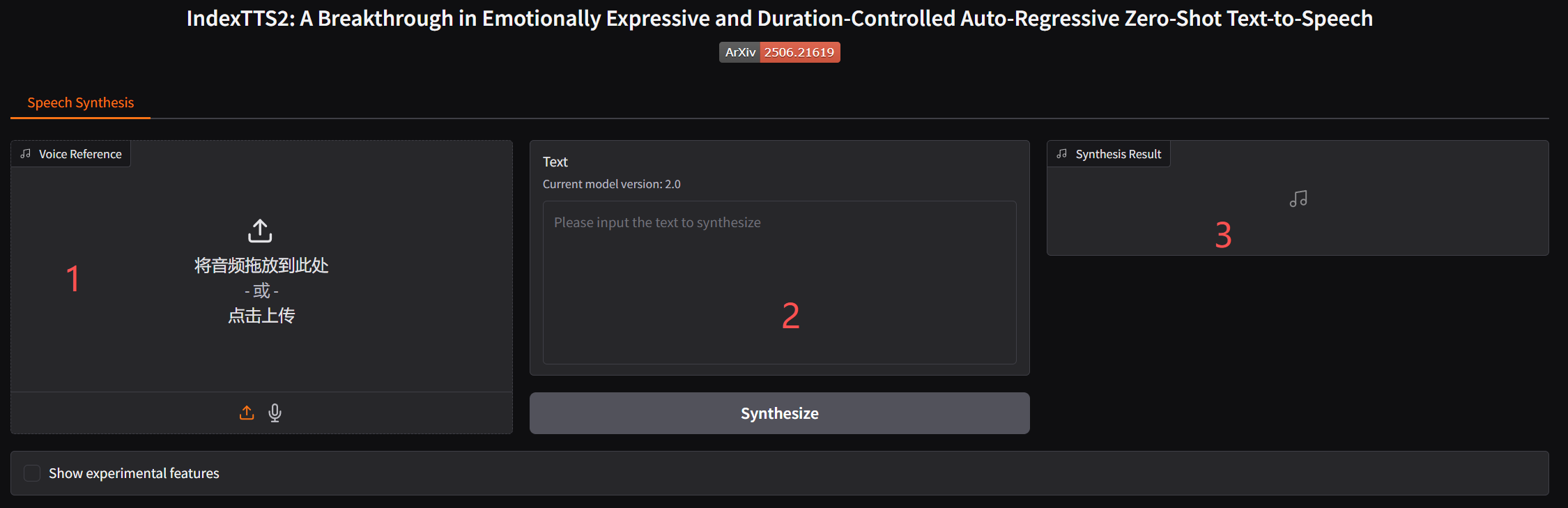
- 1 位置上传一段克隆的音频
- 2 位置输入要合成的文本,点击生成语音
- 3 播放音频,并提供下载
使用
使用官方的 demo 音频
使用以下的文本进行测试
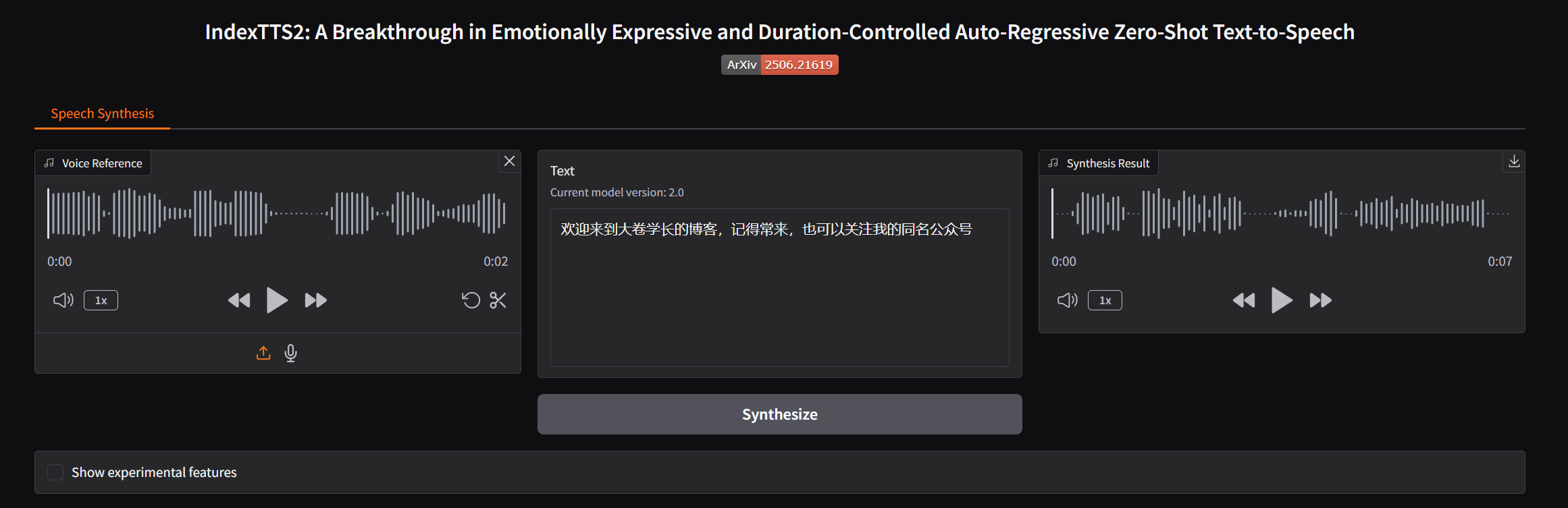
合成后的音频,效果还挺不错的,有停顿,有抑扬顿挫的感觉
IndexTTS2 这次新增了四种情感控制方式,可以实现音色与情感的独立控制。
- 与音色参考音频相同(默认):默认的方式,直接使用你上传的音色参考音频中所包含的情感特征。
- 使用情感参考音频:上传一段包含目标情感的音频作为参考,模型会提取该音频的情感特征来生成语音 。
- 使用情感向量控制:通过输入特定的情感参数来直接控制生成语音的情感倾向。
- 使用情感描述文本控制:可直接指定8维情感向量
[高兴, 愤怒, 悲伤, 害怕, 厌恶, 忧郁, 惊讶, 平静],输入通过文本描述,来引导模型生成具有相应情感倾向的语音 。
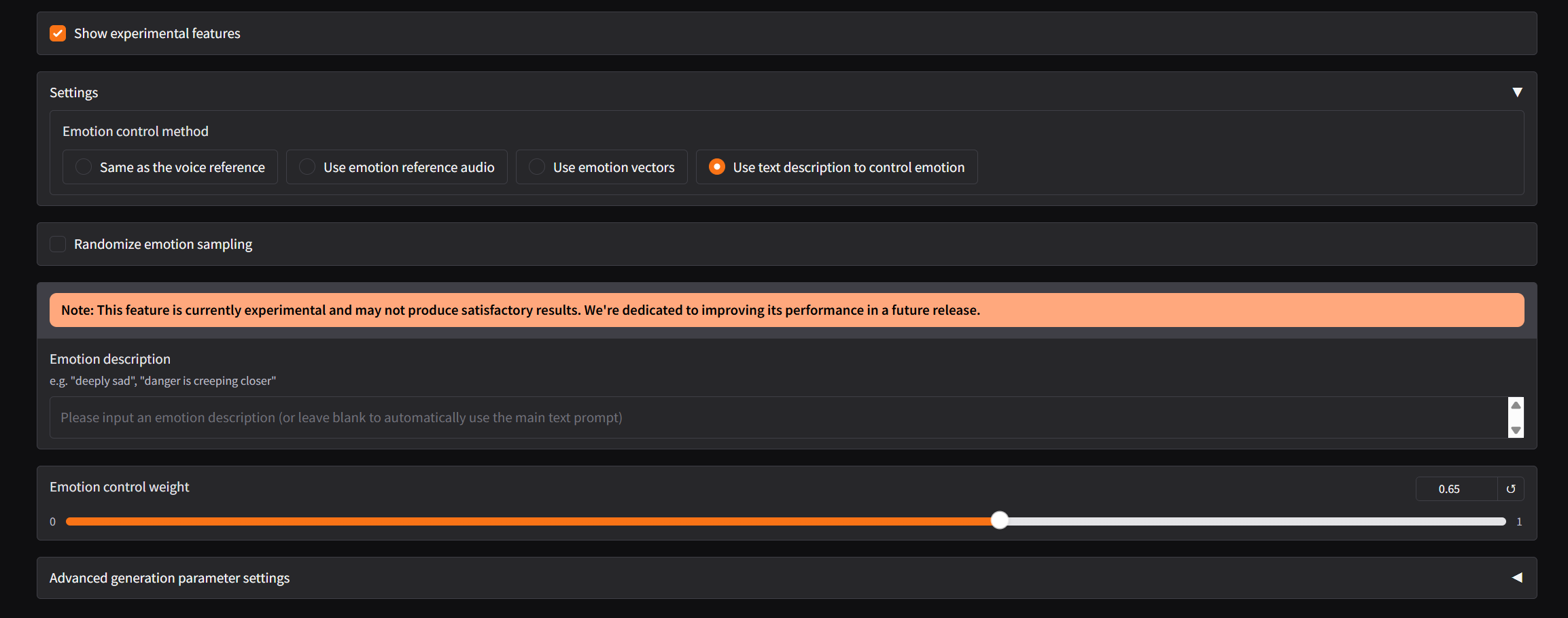
但是调整后会发现可能跟原音色会有些差别,大家可以尝试一下不同的情感变化